
搜索结果: 1-15 共查到“计算机科学技术 数据集”相关记录34条 . 查询时间(0.128 秒)
美国实验室发布超大规模有机分子数据集
美国 超大规模 有机分子 数据集
2024/1/16
美国能源部橡树岭国家实验室(ORNL)科研人员生成并发布了两个超大规模的有机分子数据集,提供了超1000万个有机分子的紫外可见光谱特性。科研人员开发了一款可扩展的工作流程软件,确保量子力学代码生成的文件得到正确处理,并使用该软件生成GDB-9-Ex数据集,再进一步扩展生成ORNL_AISD-Ex数据集。
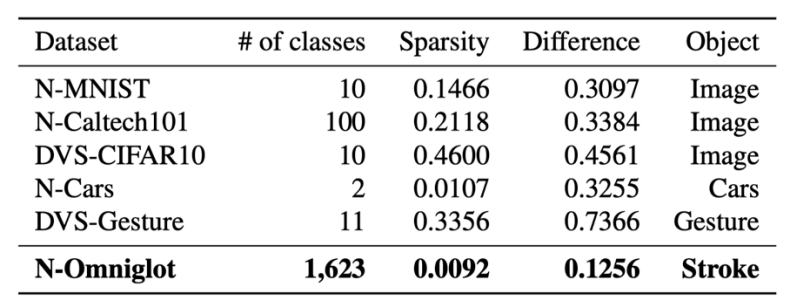
用于时空稀疏小样本学习的大规模神经形态数据集N-Omniglot(图)
时空稀疏 小样本学习 神经形态数据集
2022/12/7
中国科学院自动化研究所类脑认知智能研究组在Nature出版社旗下期刊Scientific Data上在线发表了一篇题为“N-Omniglot,a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning”的论文,提出了用于时空稀疏小样本学习的大规模神经形态数据集――N-Omniglot,为脉冲神经网络...

【自然语言处理团队】国际最大规模多模态同步语言神经影像数据集发布(图)
自然语言处理 影像数据集 语言神经 多模态
2022/10/8
大脑在加工语言时,需要实时调动多个脑区的神经元进行协同工作。构建高时空分辨率的神经影像数据可以帮助我们更好地了解各个脑区以及脑区之间的协同合作,对于研究大脑的语言加工机制至关重要。当前已有的开源数据主要针对英文采集,只包括单一模态的神经影像数据,如高空间分辨率的功能核磁共振(fMRI)或高时间分辨率的脑磁图(MEG),并且大多使用1小时以内的实验材料,数据规模有限,无法借助数据需求量大的计算模型进...

近日,南方科技大学环境科学与工程学院副教授曾振中团队联合计算机科学与工程系教授刘江团队在Science Bulletin上发表题为“An artificial intelligence reconstruction of global gridded surface winds”的研究论文。该研究为重构历史气候数据,尤其是风速数据提供了新的解决方案。

China Daily报道华中科技大学电子信息与通信学院国际学生发布首个面向非洲文字理解的公开数据集(图)
China Daily 华中科技大学电子信息与通信学院 非洲文字理解 数据集
2022/4/13
China Daily报道华中科技大学电子信息与通信学院国际学生发布首个面向非洲文字理解的公开数据集。

《慢性髓系白血病(CML)病理辅助诊断数据集要求》团体标准正式发布(图)
慢性髓系白血病 团体标准 协和医院
2022/3/19
2022年3月7日,团体标准《慢性髓系白血病(CML)病理辅助诊断数据集要求》(标准编号:T/CSBME 051―2022)在全国团体标准信息平台上正式公布。

中国科学院自动化研究所发布大规模计算机生成图像数据集(图)
中国科学院自动化研究所 计算机生成图像数据集
2021/10/25
计算机渲染技术和生成对抗网络(generative adversarial networks,GAN)的快速发展,使计算机生成图像(Computer-generated,CG)质量越来越高、越来越逼真,与相机拍摄获取的真实图像(Photographic,PG)之间的区别越来越小。高质量CG图像被恶意使用会带来信息安全隐患,例如利用逼真的CG图像制造的虚假新闻可能会引起群众恐慌。因此,研究计算机生成...

在日常购物时,我们不妨畅想一下未来商超的购物场景:无需结算台,消费者取下产品的同时,商品识别算法就可以完成自动结算;无需货架管理员,智能货架管理技术可以实时动态监测商品数量变化,并自动完成数据分析。实现这种智能化消费方式的核心难点在于解决目标检测计数联合任务领域中的遮挡问题。近日,中国科学院软件研究所智能软件研究中心发布了目前为止最大的零售场景目标检测计数联合任务数据集――Locount,该数据集...
2017金融和经济数据集与宏观建模数据科学国际研讨会(International Workshop on Data Science for Macro-Modeling with Financial and Economic Datasets)
2017 金融 经济数据集 宏观建模 数据科学 国际研讨会
2017/4/10
The promise of Big Data, linked data and social data is the availability of large scale yet granular datasets to support modeling of complex ecosystems reflecting cyber-human decision making. While co...
针对现有基于距离的离群点检测算法在处理大规模数据时效率低的问题,提出一种基于聚类和索引的分布式离群点检测(DODCI) 算法。首先利用聚类方法将大数据集划分成簇;然后在分布式环境中的各节点处并行创建各个簇的索引;最后使用两个优化策略和两条剪枝规则以循环的方式在各节点处进行离群点检测。在合成数据集和整理后的KDD CUP数据集上的实验结果显示,在数据量较大时该算法比Orca和iDOoR算法快近一个数...
基于Apriori的相容数据集间关联规则演绎方法
相容数据集 关联规则 规则演绎 Apriori算法
2013/6/12
Apriori关联规则数据挖掘算法只针对一类相关数据集进行数据挖掘,而现实世界中各种不同的数据集非常庞大,如何在不相关数据集间进行数据挖掘,拓展规则的数量具有挑战性。目前Apriori关联规则算法研究基本上集中在算法性能优化和针对不同数据形式的基础上,没有突破不相关数据集的界限。针对这个问题,首先给出了相关数据集、不相关数据集、相容数据集的概念,进一步给出了一种基于Apriori的不相关数据集中相...
当前流行的聚类集成算法无法依据不同数据集的不同特点给出恰当的处理方案,为此提出一种新的基于数据集特点的增强聚类集成算法,该算法由基聚类器的生成、基聚类器的选择与共识函数构成。该算法依据数据集的特点,通过启发式方法,选出合适的基聚类器,构建最终的基聚类器集合,并产生最终聚类结果。实验中,对ecoli,leukaemia与Vehicle三个基准数据集进行了聚类,所提出算法的聚类误差分别是0.014,0...
为处理圆柱面和圆锥面上数据集的最近邻查询问题,提出利用Voronoi图进行查询和曲面转换2种解决方法。在圆柱面和锥面上构造Voronoi图,利用Vornoi图进行查询处理。将圆柱面和锥面转换映射为二维有界平面,给出转换规则和查询算法。对2种方法进行实验分析,结果表明,利用Voronoi图的方法适合静态数据集的最近邻查询,曲面转换方法对动态数据集的最近邻查询更有效。
目前很多数据挖掘和机器学习方法都有一个基本假设:训练数据和测试数据必须服从相同的分布。但是在很多情况下这种假设不成立,没有考虑分布差异的传统机器学习方法就不能正确分类了。提出了一种新的迁移学习方法DRTAT,对原训练数据进行动态分割重组,适时地淘汰冗余数据,并进行分类器的集成。通过在多个文本数据集和UCI数据集上进行测试,并与TrAdaboost算法进行比较,表明了算法的先进性。