
搜索结果: 16-30 共查到“计算机科学技术 多模态”相关记录36条 . 查询时间(0.254 秒)
中国科学院微电子研究所等在多模态神经形态感知研究方面取得进展(图)
多模态 神经形态感知 躯体感受系统
2022/6/9
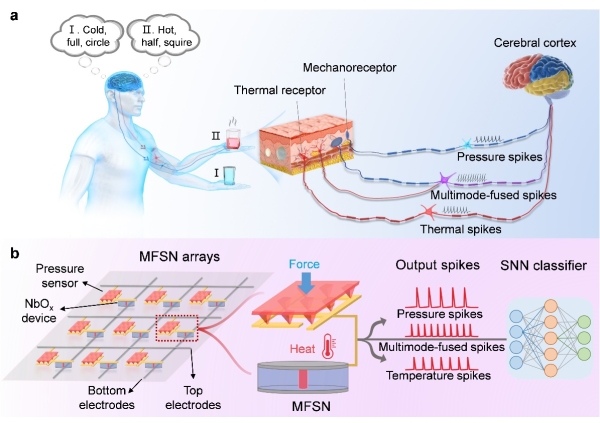
躯体感受系统中的多模态感知可帮助人们获得更全面的物体属性,并对物体的状态做出准确判断,尤其是不同受体的感觉信号在一定的条件下还可被神经元整合并发送到大脑皮层作进一步处理(图1a)。与单模态感知相比,多模态融合感知在评估物体属性和提高物体识别精度方面具有明显优势。在传统的人工感知系统中,多模态信息的处理多采用串行计算架构,传感信号需转换为数字模式才能被处理器处理,产生了较大的功耗和通信带宽开销。此外...

2022年5月24日晚,广西民族大学人工智能学院邀请同济大学百人计划、特聘研究员、博士生导师王昊奋研究员作“知识驱动的多策略多模态问答技术实践”线上主题讲座,学院副院长秦董洪及全体研究生在博达楼418室聆听。

受制于传统冯诺依曼架构下“存储墙”问题,芯片的算力难以进一步提升,限制了大数据以及人工智能等新兴信息技术产业的发展。存内计算是非冯诺依曼架构下提高芯片算力的一种有效途径,基于铁电晶体管(Fe-FET)的存算融合电路由于具有低功耗、高CMOS兼容性以及无损读出等优点,被认为是极具潜力的一种存内计算的技术方向。现已报道的Fe-FET存算电路多为单模机制。实现逻辑门电路往往需要多器件集成,或外围电路辅助...

首期人工智能创新技术讲习班“多模态认知计算与脑机智能”成功举办(图)
人工智能 多模态认知计算 脑机智能
2021/8/23
2021年8月21日-8月22日,由中国人工智能学会、浙江杭州未来科技城管委会主办,中国人工智能学会会士之家(杭州站)承办的首期人工智能创新技术讲习班“多模态认知计算与脑机智能”成功在线举办,累计在线观看人次超54万。

2021年7月24日,“2021年CAAI情感智能专委会年度会议暨多模态情感计算研讨会”在北京中科院自动化所智能化大厦报告厅召开,此次会议由中国人工智能学会主办,CAAI情感智能专委会与中科院自动化所承办,来自全国各地高等院校、科研机构、国内人机交互相关企业的近百位专家、学者、业内人士前来参会。论坛吸引了线下近100人、线上约200人参加。
2020年“多模态智能计算”国际研讨会成功举办(图)
多模态智能计算 国际研讨会
2021/1/5
2020年“多模态智能计算”国际研讨会由中国图学学会动漫图学工程专业委员会主办,大连理工大学电信学部、创新创业学院、计算机辅助设计国家地方联合工程实验室共同承办。大会主席由大连理工大学魏小鹏教授和德国哈索-普拉特纳数字工程研究院 Christoph Meinel院士共同担任。

语音情感计算及多模态交互研究团队荣获CCF A类国际顶级会议IEEE/CVF CVPR 2020超大规模商品图像检测挑战赛冠军(图)
语音情感计算 多模态交互 CCF A类 国际顶级会议 超大规模商品 图像检测 挑战赛 冠军
2020/8/12
2020年6月14―19日期间,CCF A类国际顶级会议-国际计算机视觉与模式识别大会(以下简称IEEE/CVF CVPR 2020,图1)主办的超大规模商品图像检测挑战赛(以下称“RetailVision Detection Grand Challenge”)举行了颁奖典礼。由来自语音及语言信息处理国家工程实验室语音情感计算及多模态交互研究室和中国科大信息学院自动化系组成的参赛团队(以下简称US...

多模态感觉信息整合与决策的神经机制(图)
多模态感觉 信息整合 决策 神经机制
2019/10/9
2019年10月10日,《神经元》期刊在线发表了题为《利用线性不变概率性群体编码实现基于复杂多模态感觉信息的最优决策》的研究论文,该研究由中国科学院脑科学与智能技术卓越创新中心(神经科学研究所)、中科院灵长类神经生物学重点实验室、上海脑科学与类脑研究中心空间感知研究组与瑞士日内瓦大学认知计算神经科学研究组合作完成。生物体处在一个复杂多变的环境中,不同感觉信息输入的可靠性往往随着时间发生改变。例如,...
基于稀疏表示和PCNN的多模态图像融合
信号稀疏表示 bandelet变换 几何流 脉冲耦合神经网络 图像融合
2013/4/3
提出一种基于稀疏表示和脉冲耦合神经网络(pulse coupled neural network, PCNN)的新方法。首先将原图像进行bandelet变换,提取出图像中的几何流和bandelet系数等重要信息,再利用PCNN进行几何流融合、根据稀疏相似度优化融合后的几何流,然后更新部分bandelet系数并根据最大绝对值规则进行融合,最后通过bandelet逆变换得到融合后的图像。仿真实验结果表...
基于多模态信息融合的新闻独白镜头检测
独白镜头检测 新闻视频 视频检索
2009/10/12
新闻视频中的独白镜头具有较大的信息量,在视频检索和挖掘中具有较高的应用价值。提出了一种融合音频、视频、时域以及上下文信息等多模态特征进行独白场景检测的方法。首先利用规则移除广告和“其他”镜头,然后应用聚类的方法检测主持人镜头,最后应用条件随机场(CRFs)模型标记独白和记者镜头。该方法无需额外的信息,具有较好的普适性,实验取得了较好的性能。
基于LBP和Fisherfaces的多模态人脸识别
局部二值模式 Fisherfaces方法 多模态人脸识别
2009/8/19
提出一种结合局部二值模式(LBP)和Fisherfaces的多模态人脸识别方法。用LBP算子提取人脸灰度图像和深度图像的区域LBP直方图序列(LBPHS),再采用Fisherfaces分别构建相应的线性子空间,用余弦相似度作为投影向量的相似度量,用加权求和规则进行信息融合。在FRGC数据库上的实验结果表明,该方法要明显优于LBPHS与直方图交及Fisherfaces与余弦相似度的融合,等错误率仅为...
多模态人脸识别融合方法比较研究
Fisherfaces 多模态人脸识别 融合
2009/7/23
比较研究了多模态人脸识别中的5种匹配得分级融合方法。首先用局部二值模式(Local Binary Pattern,LBP)算子分别提取人脸灰度图像和深度图像的区域LBP直方图序列(LBP Histogram Sequence,LBPHS),采用Fisherfaces分别构建相应的线性子空间,用余弦相似度计算投影向量的匹配得分,再采用5种方法对匹配得分进行融合。在FRGC数据库上的实验结果表明,除最...
基于文本及视音频多模态信息的新闻分割
直方图 语谱图 视频分割
2009/7/2
提出了一种融合文本和视音频多模态特征的电视新闻自动分割方案。该方案充分考虑各种媒体特征的特点,先用矢量模型和GMM对文本进行预分割,用语谱图和HMM对语音预分割、用改进的直方图和SVM分类器对视频进行预分割。然后在时间同步的基础上,使用复合策略用ANN对预分割的数据进行融合,从而获得具有一定语义内容的视频段。实验结果表明此方法的有效性,并且分割后的视频片段具备较完整的语义信息特征,避免了分割的过度...