
搜索结果: 1-14 共查到“计算机科学技术 语言模型”相关记录14条 . 查询时间(0.126 秒)

通用人工智能(AGI)一直是人工智能研究的长期目标,是一项充满挑战性的课题。最近,以ChatGPT为代表的大语言模型在通用人工智能方面取得重要进展,引发了自然语言处理领域深刻的技术变革,随后迅速蔓延至其它领域,产生广泛而深远的影响。本报告将重点介绍大语言模型的发展脉络,并剖析其背后的自然语言处理技术,在此基础上总结大语言模型技术带来的机遇与挑战。
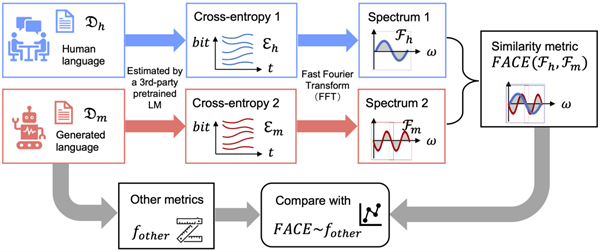
语言大模型是当前研究热点,但如何评估机器生成的语言与人类自然语言的差异是一个关键且困难的问题。南方科技大学计算机科学与工程系计算语言学与意识科学(CLCS)课题组对这一问题进行了深入研究,提出了一种基于信息熵频谱分析的新型方法。这种方法可有效地用于评估大语言模型(large language models, LLMs)的生成质量,并检测与人类自然语言的区别。这种新型方法的灵感来源于心理语言学领域中...

前沿丨人工智能学院计智伟课题组提出蛋白互作预测的语言模型(图)
计智伟课题组 蛋白互作预测 语言模型
2023/7/23
2023年7月21日,生物信息领域重要期刊Briefings in Bioinformatics在线发表了南京农业大学人工智能学院计智伟教授课题组的题为“HNSPPI: A Hybrid Computational Model Combing Network and Sequence Information for Predicting Protein-Protein Interaction”的研...

中国科学院声学研究所专利:一种基于长短时记忆网络的语言模型重估方法
融合预训练语言模型和标签依赖知识的关系抽取方法
关系抽取 预训练模型 标签依赖 图卷积神经网络
2022/2/28
关系抽取旨在从未经标注的自由文本中抽取实体间的关系。然而,现有的方法大都孤立地预测每一个关系而未考虑关系标签相互之间的丰富语义关联。该文提出了一种融合预训练语言模型和标签依赖知识的关系抽取模型。该模型通过预训练模型BERT编码得到句子和两个目标实体的语义信息,使用图卷积网络建模关系标签之间的依赖图,并结合上述信息指导最终的关系分类。实验结果显示,该文方法性能相较于基线方法得到了显著提高。
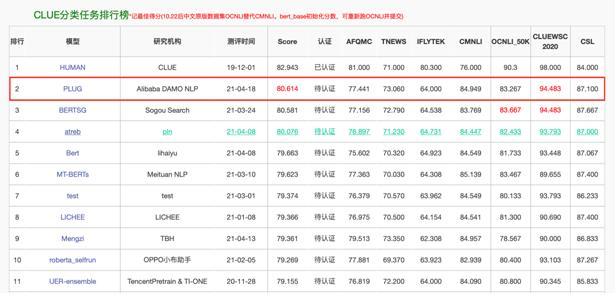
2021年4月19日,阿里巴巴达摩院发布超大规模语言模型PLUG,该模型参数规模达270亿,是目前全球规模最大的中文纯文本预训练语言模型。PLUG集良好的语言理解与创造性文本生成能力于一身,在小说仿写、诗歌生成、智能问答等长文本生成领域表现突出,其目标是通过超大模型的能力,大幅提升中文自然语言技术在各类任务中的表现。
利用覆盖歧义检测法和统计语言模型进行汉语自动分词
统计语言模型 覆盖歧义检测法 自动分词
2009/4/27
该文探讨了利用覆盖歧义检测法和统计语言模型进行汉语自动分词的问题。采用了多次迭代的方法来进行汉语词层面统计语言模型的训练。该方法能够得到更优化的语言模型。该文详细介绍了统计语言模型的训练过程,给出了语言模型复杂度随迭代次数增加而减小的实验结果。还给出了在不同的统计语言模型阶数下切分正确率变化的情况,分析了切分正确率变化的原因。
信息检索中语言模型的研究
语言模型 信息检索 平滑 反馈
2008/12/30
介绍了最新被应用于信息检索领域的模型――语言模型。论述了构造应用于信息检索语言模型的3个步骤,介绍了这种语言模型的排序方法、反馈和与其它因素结合的方法,以及其在检索领域的应用效果,提出了语言模型在信息检索中的发展方向。
随着Internet以及Intranet中大量可利用信息的爆炸式增长,文本分类成为处理和组织大量文档数据的关键技术之一。该文提出一种本体论和统计方法相结合的混合语言模型,用以解决自动文本分类问题。首先,通过学习不同类别的训练语料,分别获得各自类别的语言本体知识库,构造成为不同类别的分类器。对于实际文档,将基于不同类别的语言本体知识库分别获得对文档的评价值,并以所获得的最高评价值决定该文档的类别归属...
一种新颖的词聚类算法和可变长统计语言模型
词的聚类 统计语言模型 可变长模型
2007/12/28
基于类的统计语言模型是解决统计模型数据稀疏问题的重要方法.但该方法的两个主要瓶颈在于:(1)词的聚类.目前我们很难找到一种比较成熟且运算量适中、收敛效果好的聚类算法.(2)基于类的模型为增强对不同领域语料的适应能力往往牺牲了一部分预测能力.该文的工作就是围绕这两个瓶颈问题展开的.在词的聚类方面,作者基于自然语言词与词之间的相似度,提出了一种词的分层聚类算法.实验证明,该算法在算法复杂度和聚类效果上...
语义分析和结构化语言模型
2007/11/2
Li MQ, Li JZ, Wang ZY, Lu DJ. Semantic analysis and structured language models.
Journal of Software, 2005,16(9):1523-1533.DOI:
10.1360/jos161523 http://www.jos.org.cn/1000-9825/16/1523.htm摘要
提...
一种新的语言模型判别训练方法
语言模型 判别训练 损失函数 日文输入法
2007/11/1
已有的一些判别训练(discriminative training)方法如Boosting[1]为了提高算法的效率,要求损失函数(loss function)是可以求导的,这样的损失函数无法体现最直接的优化目标.而根据最直接优化目标定义的损失函数通常是不可导的阶梯函数的形式.为了解决上述问题,文章提出了一种新的判别训练的方法GAP(Greedy Approximation Processing)....
基于统计语言模型的信息检索
2007/7/28
期刊信息
篇名
基于统计语言模型的信息检索
语种
中文
撰写或编译
撰写
作者
李晓光,王大玲,于戈
第一作者单位
刊物名称
计算机科学,
页面
Vol.32,No.8,pp124-127, 2005.8
出版日期
2005年
8月
日
文章标识(ISSN)
相关项目
Internet上支持高质量E-Services的零输入个性化技术的研究