
搜索结果: 1-15 共查到“计算机应用 文本”相关记录72条 . 查询时间(0.15 秒)
本文以"基因编辑婴儿"为案例,通过网络爬虫技术爬取果壳网、央视新闻等7个微博账号,以其中的165条事件相关微博原文和6440条微博评论为样本进行框架分析,并以恩克曼六种基本情绪指标对评论进行分类。研究发现,"基因编辑婴儿"事件相关微博文本中存在"个人问责""外部问责"等十个框架。在描述分析基础上,研究利用对应分析(correspondence analysis)检验微博原文框架、评论框架、评论情绪...
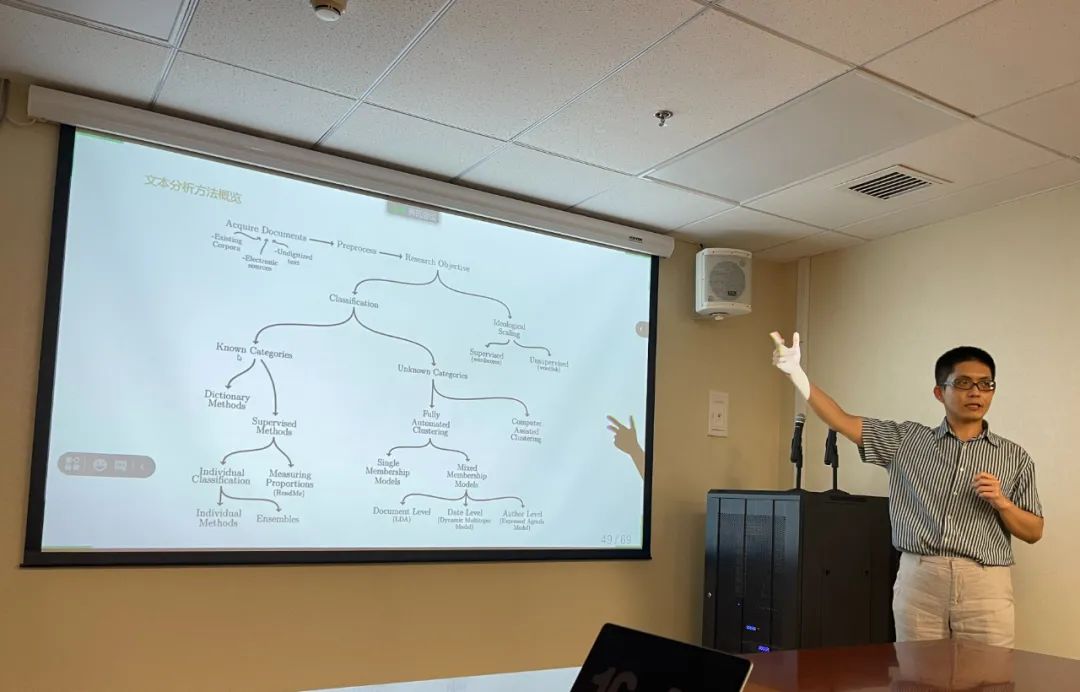
清华大学社会科学学院政治学系副教授胡悦受邀出席傅璇琮学术讲座并做主题发言:计算机辅助文本分析概论(图)
清华大学社会科学学院政治学系 胡悦 傅璇琮 学术讲座 计算机辅助文本分析概论
2021/7/26
2021年7月24日下午,“傅璇琮学术讲座”第二十四讲在清华大学蒙民伟人文楼124室举行。应清华大学中文系邀请,清华大学政治学系副教授胡悦作了题为“计算机辅助文本分析概论”的主题讲座。此次讲座由清华大学中文系副教授李飞跃主持,北京邮电大学人文学院武永老师及数十名校内外师生出席。
延安大学数学与计算机学院网页制作课件第十三章 格式化文本
延安大学数学与计算机学院 网页制作 课件 第十三章 格式化文本
2018/3/22
延安大学数学与计算机学院网页制作课件第十三章 格式化文本。
石河子大学机械电气工程学院计算机绘图课件第五讲 文本标注
石河子大学机械电气工程学院 计算机绘图 课件 第五讲 文本标注
2016/3/10
石河子大学机械电气工程学院计算机绘图课件第五讲 文本标注。
为有效提高非结构化Web金融文本情感倾向和强度分析的精度,提出了基于语义规则的Web金融文本情感分析算法(SAFT-SR)。该算法基于Apriori算法对金融文本进行属性抽取,构建金融情感词典和语义规则识别情感单元及强度,进而得到文本的情感倾向和强度。实验结果表明,与Ku提出的算法相比,在情感倾向分类方面,算法SAFT-SR情感分类性能良好,提高了分类器的F值、查全率和查准率;在情感强度计算方面,...

殷绪成博士团队携“自然场景文本检测技术”斩获国际大奖(图)
殷绪成 自然场景文本检测技术 国际大奖
2013/9/4
近日,2013年国际文档分析与识别大会在美国华盛顿召开了。作为大会的重要环节之一,大会揭晓了2013年国际文档分析与识别竞赛结果,北京科技大学的殷绪成博士团队获得本届大赛最受关注的Robust Reading Competition竞赛三项冠军,其中“自然场景文本检测”项目,是中国研究机构首次问鼎此项目冠军。
现有的海量日志统计分析方法速度慢,且对硬件配置的要求高。为此,提出一种基于文本策略和SMCS的海量日志分析方法。根据文件的软件设计策略,采用日志文件索引方法,将日志文件与日志时间关联,以加快日志提取。SMCS算法采用哈希表、文件归并、堆操作方法对海量日志进行统计分析和内存损耗控制。通过对真实软件进行对比实验,结果表明,该方法的分析速度比传统方法提高4倍。
基于非负矩阵分解的双重约束文本聚类算法
半监督聚类 非负矩阵分解 成对约束 类别约束
2011/12/20
提出一种基于非负矩阵分解(NMF)的双重约束文本聚类算法。在正交三重NMF模型中,加入文本空间的成对约束信息和词空间的类别约束信息,将不同的特征词项进行分类。利用迭代规则对原始的词-文档矩阵进行分解,获得文本聚类结果。与多种传统半监督文本聚类算法的对比结果表明,该算法具有较高的聚类精度,能提供更准确和有效的聚类结果。
基于本体及相似度的文本聚类研究
本体 相似度 文本聚类 语义
2010/7/1
为了改善文本聚类的质量,得到满意的聚类结果,针对文本聚类忽略概念的内涵及缺少概念间的联系,设计和改进了基于本体和相似度的文本聚类方法TCBOS(text clustering based on ontology and similarity)。研究了文本预处理及分词的方法,设计了用有限状态自动机来自动提取概念和关系的方法,对概念语义扩展和相似度计算方法进行了改进和完善,通过应用本体的语义相似度来...
基于双混沌映射的文本hash函数构造
混沌 hash函数 Logistic映射 斜帐篷映射
2010/7/1
提出了一种基于混沌Logistic 映射和斜帐篷映射的文本hash函数算法。该算法将明文信息分组并转换为相应的ASCII码值,然后把该值作为Logistic映射的迭代次数,迭代生成的值作为斜帐篷映射的初始值进行迭代,然后依据一定的规则从生成值中提取长度为128 bit的hash值。通过仿真对该算法的单向性、混乱与扩散、碰撞等性能进行分析,理论分析和仿真实验证明该算法可以满足hash函数的各项性能要...
漏洞数据库的文本聚类分析
漏洞数据库 文本聚类 聚类重叠指标 主导漏洞类型
2010/7/1
为解决现有软件漏洞分类重叠性和实用性低等问题,提出了在漏洞实例聚类基础上的漏洞分类方法。对漏洞数据库(national vulnerability database, NVD)的漏洞描述字段进行文本聚类,并且使用聚类重叠性指标评估Simplekmean、BisectingKMeans和BatchSom聚类算法的效果,依据领域主导度选择典型的漏洞类型。实验结果显示近NVD中四万条漏洞数据聚类成45类...
针对大多数基于向量空间模型的中文文本聚类算法存在高维稀疏、忽略词语之间的语义联系、缺少聚簇描述等问题,提出基于语义列表的中文文本聚类算法CTCAUSL(Chinese text clustering algorithm using semantic list)。该算法采用语义列表表示文本,一个文本的语义列表中的词是该文本中出现的词,从而降低了数据维数,且不存在稀疏问题;同时利用词语间的相似度计算解...
基于游程特征的文本图像识别方法
图像识别 游程特征 倾斜度
2010/3/2
提出了一种基于游程特征的中英文本图像识别方法,用游程统计特征提供的图像信息作为图像模式识别的描述特征,在此基础上利用神经网络来训练分类器。实验结果表明,该方法的识别精度较高,具有一定的容错能力。
基于语义特征的文本情感倾向识别研究
语义特征 倾向识别 情感分类 主题分类
2010/3/1
由于网络评论用语的多样性,常用的文本主题分类方法并不能完全适应情感倾向识别。针对这个问题,从语义理解的角度出发,提出一种基于语义特征的情感倾向识别方法,通过增加语义特征使得原始文本表现出更加明确的情感倾向,并且更加容易区分。实验结果表明了该方法的有效性。